Table of Contents
实验室简介
实验室聚焦生物多尺度信息融合难点,通过结合高性能计算和人工智能算法,解决生物医药科学中的重大问题,为生物医药产业赋智赋能,开发准确且超快的疾病诊疗和新药研发算法,并基于“天河二号”构筑大数据分析和计算统一的云超算平台,为产学研应用提供一站式服务。
随着健康大数据的快速发展,健康医药已成为AI产业应用的一个热点,腾讯、阿里、华为等公司均纷纷布局相关产业开发,而今年的抗击疫情充分展示了大数据分析在人类健康中的重要作用。疫情期间,本实验室充分利用“天河二号”的超强算力,开展了基于CT的智能诊断、药物智能推荐算法、及医药知识图谱等一系列工作,取得了多项重要成果。项目涉及CV、NLP、ML、知识图谱等多个领域,广泛运用到了各种前沿AI技术,对任意技术感兴趣的同学都能在这里找到属于自己的舞台。我们与其他大多数AI实验室所不同的地方在于更着重于培养学生解决真实物理世界难题,研究过程中学会发现、分析、并解决问题,也更容易被IT大公司所青睐。
很多计算机背景同学看到我们的介绍就望而止步,误解需要大量的生物化学学习,实际上我们的重点是研究计算机算法去解决生物医药的问题,核心还是算法,研究组的学生绝大多数是计算机背景,当然适当的生化知识对深入的研究有很好的支持。实验室鼓励学生去国内外著名大学深造,实验室的AI+Science研究方向更合适有科学研究抱负的同学,有更深远的发展空间。
实验室毕业生出路较好:博士生大多毕业即入职头部高校的教职或准教职岗位,硕士基本都入职头部IT公司。
参考实验室成员撰写的 《计算机本科生参与科研心得体会》:全文链接
- 实验室长期招聘研究生、博士生、博士后。计算机及相关研究方向背景合适的学者也可以向学院推荐申请副教授或教授职位。
- 生物、医学等交叉学科的同学欢迎报考我和中山大学孙逸仙纪念医院联合培养的“健康数据科学”学位,培养方式类似,学位为中山医学位 (对该类感兴趣的联系时请注明)。
欢迎感兴趣的本科生联系。目前主要研究内容包括多个维度:生物分子的几何图网络表征,大模型+知识图谱驱动的多尺度组学数据挖掘、融合分子模拟的药物分子智能设计,基于“天河二号”的生物医药高性能计算平台研发及应用(平台及应用)。

代表性论文
- Zheng S, Y Li, S Chen, J Xu* and Yuedong Yang* . Predicting Drug Protein Interaction using Quasi-Visual Question Answering System. Nature Machine Intelligence 2020;2(1):134-140 PDF (将药物设计转化为经典VQA问题;2021年世界人工智能大会青年优秀论文奖).
- Zheng S, Tan Y, Wang Z, Li C, Zhang Z, Sang X, Chen H, Yuedong Yang* . Accelerated rational PROTAC design via deep learning and molecular simulations. Nature Machine Intelligence 2022;4:739–748 PDF. (超快速PROTAC药物设计和实验验证)
- Y Zeng, M Luo, N Shangguan, P Shi, J Feng, J Xu, K Chen, Y Lu, W Yu, and Yuedong Yang*. Deciphering Cell Types by Integrating scATAC-seq Data with Genome Sequences. Nature Computational Science 2024;4:285–298 . (利用基因序列引导实现组学数据降噪)
- Y Zeng, J Xie, N Shangguan,Z Wei, W Li, Y Su, S Yang, C Zhang, J Zhang, N Fang, H Zhang, Y Lu, H Zhao, J Fan, W Yu, Yuedong Yang. CellFM: a large-scale foundation model pre-trained on transcriptomics of 100 million human cells. Nature Communications 2025;16,4679. (华为昇腾芯片训练1亿人类细胞的8亿参数的单细胞大模型,当前该类最大模型)
- J Rao, J Xie, Q Yuan, D Liu, Z Wang, Y Lu*, S Zheng*, Yuedong Yang*. A Variational Expectation-Maximization Framework for Balanced Multi-scale Learning of Protein and Drug Interactions. Nature Comm 2024 ( 基于Expectation-Maximization实现多尺度信息融合)
- Y Song, Q Yuan, S Chen, Y Zeng, H Zhao, Yuedong Yang*. Accurately predicting enzyme functions through geometric graph learning on ESMFold-predicted structures. Nature Comm 2024 (Accepted) (基于结构的蛋白质酶功能准确预测)
- Zheng S, T Zeng, C Li, B Chen, CW Coley, Yuedong Yang* , Ruibo Wu*. Deep learning driven biosynthetic pathways navigation for natural products with BioNavi-NP. Nature Comm 2022;13:3342 (天然产物逆合成预测;中国日报网海外版专题报道“Supercomputer, AI to speed up drug discoveries”)
- Qiu J#, Xie J#,Su S, Gao Y, Meng H, Yuedong Yang* , Liao K*. Selective functionalization of hindered meta-C–H bond of o-alkylaryl ketones promoted by automation and deep learning. Chem 2022; doi:j.chempr.2022.08.015 PDF. (自动化和智能化结合加速化学反应预测;科学网报道)
- S Chen, J Xie, R Ye, DD Xu, Yuedong Yang*. Structure-Aware Dual-Target Drug Design through Collaborative Learning of Pharmacophore Combination and Molecular Simulation. Chemical Science 2024; 15, 10366-10380 (Cover Story) (一药双靶的药物智能设计.]]
- Zheng S#, Rao J#, Song Y, Zhang J, Xiao X, Fang EF, Yuedong Yang* , Niu Z*. PharmKG: A Dedicated Knowledge Graph Benchmark for Biomedical Data Mining. Brief in Bioinfo 2020;bbaa344 PDF (PharmKG与Alphafold、IBM Waston等一起,被英国调研机构Deep Pharma Intelligence列为2018-2020年国际AI制药十大进展)
AI for Science基础理论方法
1) 科学大模型&智能体
- Y Zeng, J Xie, Z Wei, Y Su, N Shangguan, S Yang, C Zhang, W Li, J Zhang, N Fang, H Zhang, H Zhao, Y Lu, J Fan, W Yu, Yuedong Yang. Nature Communications 2025;16,4679. (世界最大的单细胞大模型:一亿细胞数目,8亿参数)
- S Zheng, J Rao, J Zhang, C Li, Yuedong Yang*. Cross-modal Graph Contrastive Learning with Cellular Images. Advanced Science 2024; doi: 10.1002/advs.202404845. (融合表型的药物大模型)
- M Zhu, J Rao, X Chen, Q Yuan, Yuedong Yang. Advancing Protein Design via Multi-Agent Reinforcement Learning with Pareto-Based Collaborative Optimization. AAAI 2026. (多智能体协同优化)
2) 图神经网络算法
- J Rao, D Xu, W Wei, Y Chen, M Yang, Yuedong Yang. Quadruple Attention in Many-body Systems for Accurate Molecular Property Predictions. ICML 2025. (多体图网络)
- Rao J, Zheng S, Yuedong Yang*. Quantitative Evaluation of Explainable Graph Neural Networks for Molecular Property Prediction. Patterns 2022;100628. (图神经网络的可解释定量评估系统)
- Chen J#, Zheng S#, Yuedong Yang*. Learning Attributed Graph Representation with Communicative Message Passing Transformer. IJCAI 2021. (综合CMPNN和Transformer的新型图卷积框架)
3) 多模态方法
- J Rao, H Lin, L Chen, J Xie, S Zheng, Yuedong Yang. Multi-modal Contrastive Learning with Negative Sampling Calibration for Phenotypic Drug Discovery. CVPR 2025.
- Rao J, Zheng S, Mai S, Yuedong Yang*.Communicative Subgraph Representation Learning for Multi-Relational Inductive Drug-Gene Interaction Prediction. IJCAI 2022. (基于子图预测的药物-基因相互作用预测)
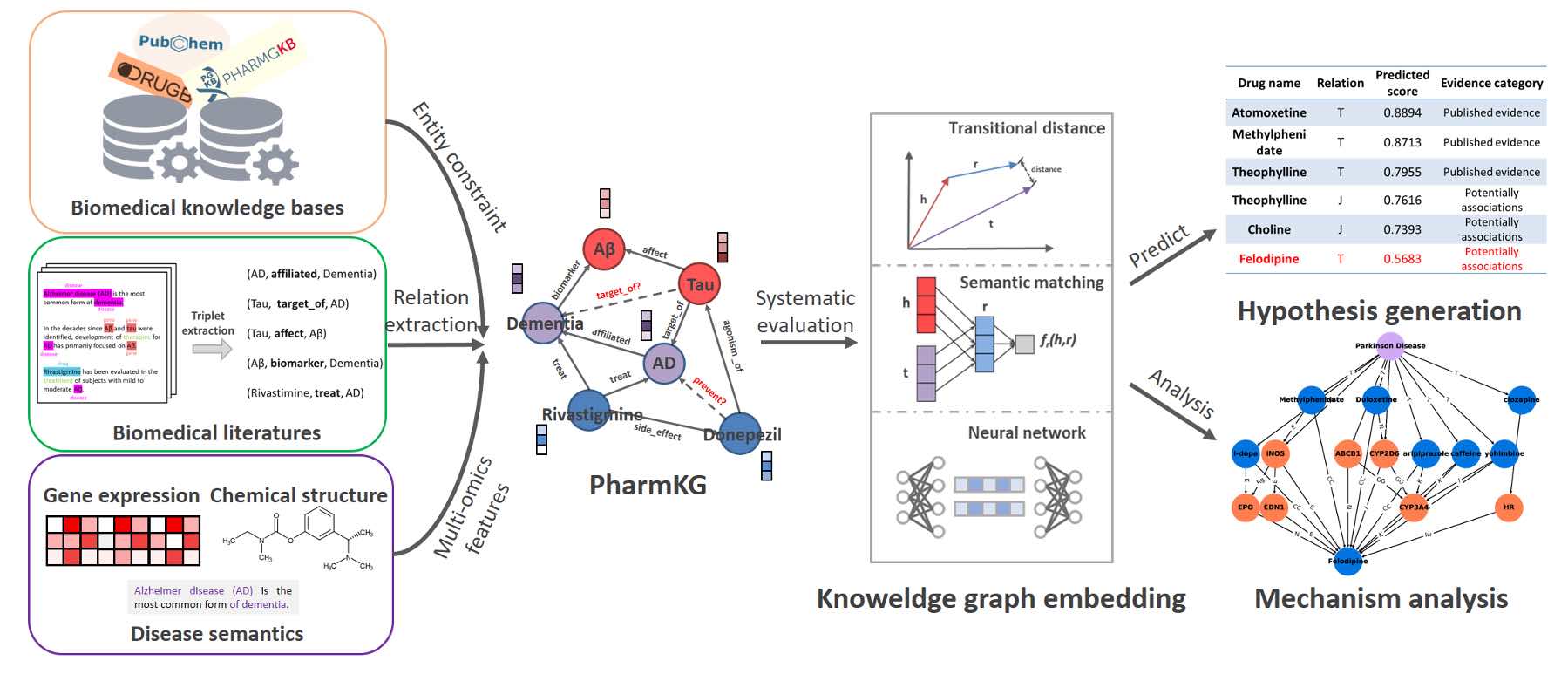
- Zheng S#, Rao J#, Song Y, Zhang J, Xiao X, Fang EF, Yuedong Yang*, Niu Z*. PharmKG: A Dedicated Knowledge Graph Benchmark for Biomedical Data Mining. Brief in Bioinfo 2020; doi:10.1093/bib/bbaa344. (最早的药物知识图谱之一,通过整合OMIM、DrugBank等多个相关公共知识数据库,并从最新文献数据库进行知识抽取,结合人工和算法进行精细的数据清洗和实体性质对齐,最终包括基因、药物和疾病三大类共8000余种实体、和它们之间29类50多万个相互关系)
- Zheng S, S Mai, Y Sun, H Hu*, Yuedong Yang*. Subgraph-aware Few-Shot Inductive Link Prediction via Meta-Learning. IEEE TKDE 2022; DOI: 10.1109/TKDE.2022.3177212 . (基于元学习的连接归纳预测)
- Mai S#, Zheng S#, Yuedong Yang*, Hu H*. Communicative Message Passing for Inductive Relation Reasoning. AAAI 2021(基于归纳的知识推导CoMPILE算法)
蛋白质结构和功能预测
蛋白质是生物体最重要大分子之一,参与几乎所有的生命活动,准确预测蛋白质三维空间结构和折叠过程被列为21世纪重大科学难题之一。从2013年起,PI就利用深度学习技术开发出蛋白质二级结构预测SPIDER系列,是国际上最早将深度学习用于蛋白质二级结构预测的研究之一,此后不断引入多任务学习、模型的迭代训练等策略,并将结构预测从以前的二级结构离散状态转换为连续数值预测。
1) 蛋白质功能预测
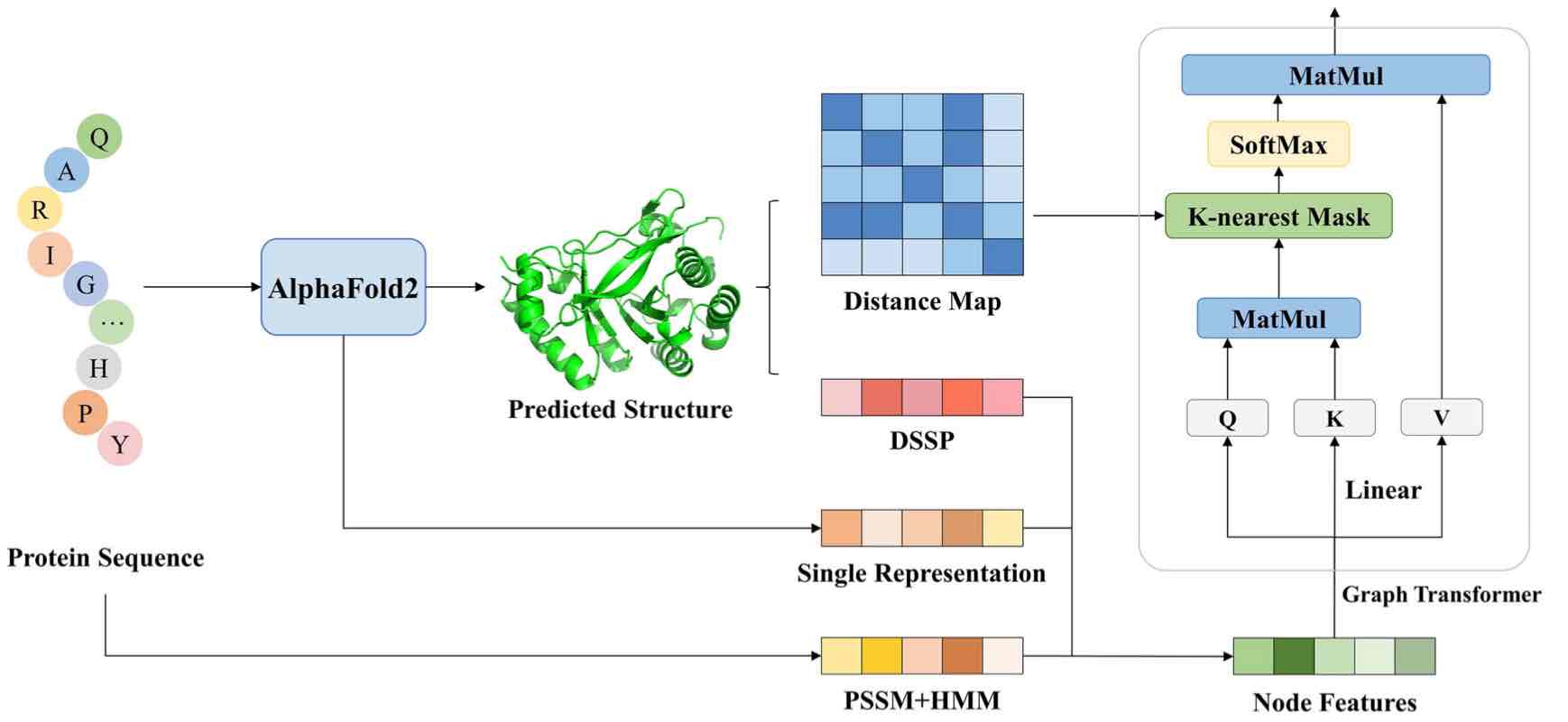
- Y Zeng, Z Wei, Q Yuan, S Chen, W Yu, Y Lu, J Gao, Yuedong Yang*. Identifying B-cell epitopes using AlphaFold2 predicted structures and pretrained language model. Bioinformatics 2023; btad187 (结合AF2预测结构和蛋白序列语言大模型的蛋白质性质预测)
- Yuan Q, Chen S, Rao J, Zheng S, Zhao H, Yuedong Yang*. AlphaFold2-aware protein-DNA binding site prediction using graph transformer. Brief in Bioinfo 2022; bbab564 . (基于Alphafold2预测模型的位点预测)
- Yuan Q, Chen J, Zhao H, Zhou Y*, Yuedong Yang*. Structure-aware protein-protein interaction site prediction using deep graph convolutional network. Bioinformatics 2021; btab643. (利用GCN从三维结构预测结合位点)
- Chen J, Zheng S, Zhao H, Yuedong Yang*. Structure-aware Protein Solubility Prediction From Sequence Through Graph Convolutional Network And Predicted Contact Map. J Cheminfo 2021; 13(1):7 (首次利用预测接触图和GCN实现从序列的蛋白质预测)
2) 蛋白质结构性质预测
- J Lyons, A Dehzangi, R Heffernan, A Sharmaa, K Paliwal, A Sattar, Y Zhou*, Yuedong Yang*. Predicting backbone Calpha angles and dihedrals from protein sequences by stacked sparse auto-encoder deep neural network. J Comput Chem. 2014; 35(28):2040-6. doi: 10.1002/jcc.23718. (SPIDER,国际上最早将深度学习用于蛋白结构预测预测工作之一)
- Yuedong Yang , J Gao, J Wang, R Heffernan, J Hanson, K Paliwal, and Y Zhou. Sixty-five years of long march in protein secondary structure prediction: the final stretch? Brief in Bioinfo 2018 May 1;19(3):482-494. (SPIDER,二级结构预测)
- Heffernan R, Yuedong Yang*, Paliwal K, Zhou Y*. Capturing Non-Local Interactions by Long Short Term Memory Bidirectional Recurrent Neural Networks for Improving Prediction of Protein Secondary Structure, Backbone Angles, Contact Numbers, and Solvent Accessibility. Bioinformatics. 2017 Sep 15;33(18):2842-2849.
3) 蛋白质三维结构预测
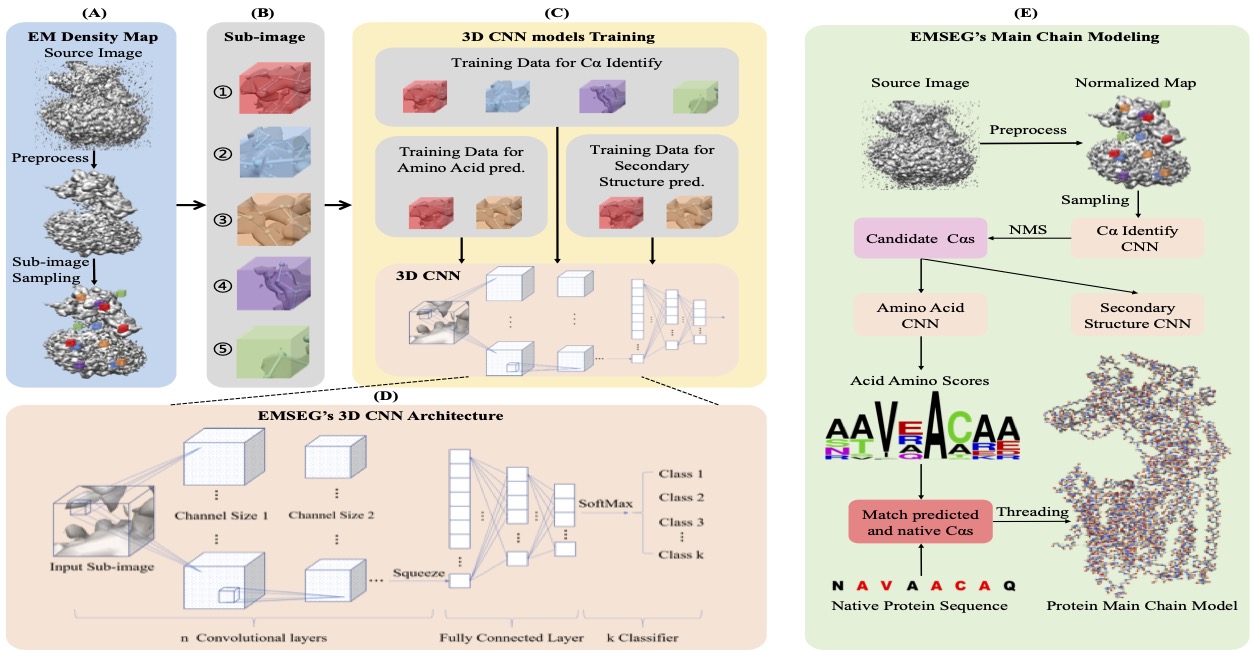
- Chen S, Zhang S, Li X, Liu Y, and Yuedong Yang*. SEGEM: a Fast and Accurate Automatic Protein Backbone Structure Modeling Method for Cryo-EM. BIBM 2021. (基于AI的冷冻电镜结构自动建模;基于该模型,在国家蛋白质科学中心、阿里云、Intel联合举办的冷冻电镜复合物结构建模中荣获冠军,并大幅领先其他模型)
- Yuedong Yang, Faraggi E, H Zhao, Zhou Y. Improving protein fold recognition and template-based modeling by employing probabilistic-based matching between predicted one-dimensional structural properties of the query and corresponding native properties of templates. Bioinformatics 2011 Aug 1;27(15):2076-82. (SPARKS,基于模板的三维结构预测)
- Cai Y, Li X, Sun Z, Lu Y, Zhao H, Hanson J, Paliwal K, Litfin T, Zhou Y*, Yuedong Yang*. SPOT-Fold: Fragment-Free Protein Structure Prediction Guided by Predicted Backbone Structure and Contact Map. J Comput Chem. 2020 Mar 30;41(8):745-750. (结合预测性质和分子动力学模拟的从头结构建模)
药物智能设计
围绕药物设计全流程,开发了基于AI的全流程算法,包括药物筛选、分子优化、ADMET性质预测、化学合成路线预测等。相关代表性工作包括:
1) 药物筛选
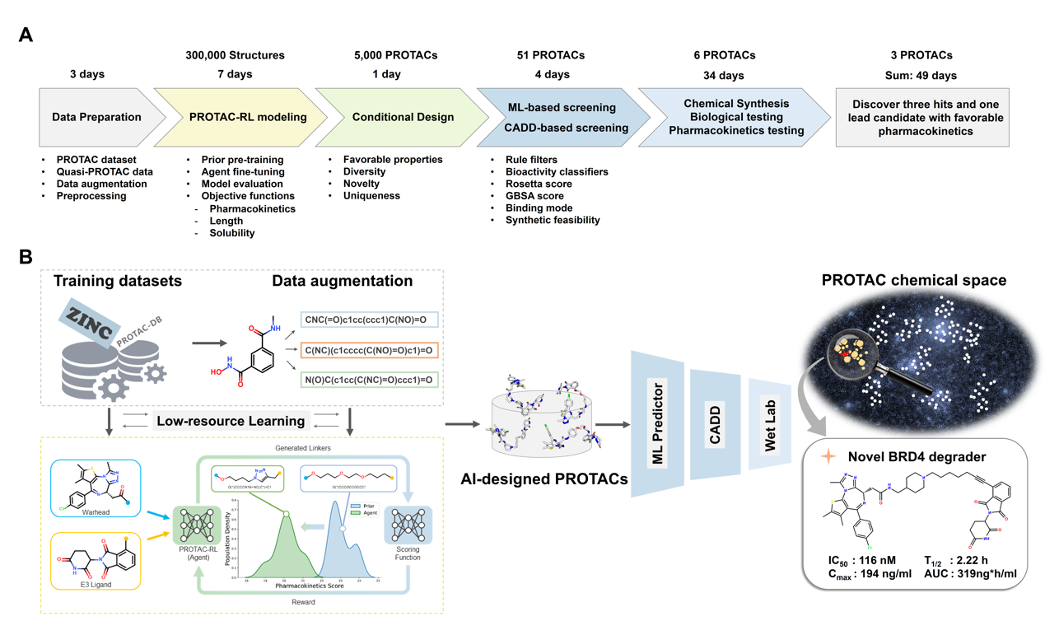
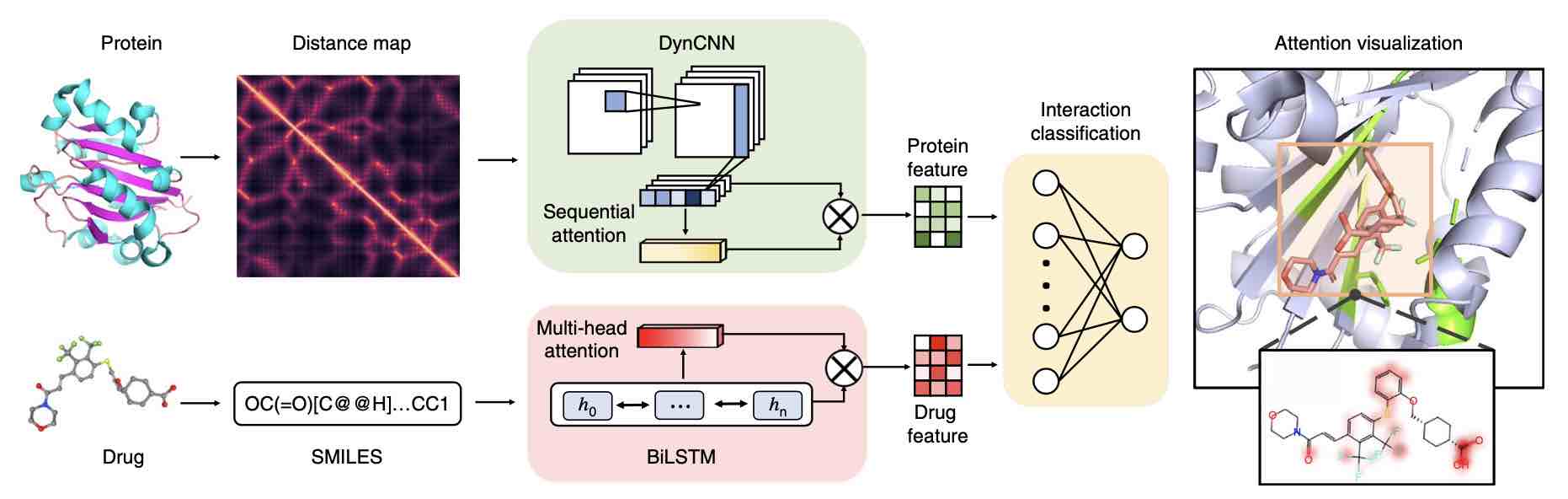
- Zheng S, Tan Y, Wang Z, Li C, Zhang Z, Sang X, Chen H, Yuedong Yang*. Accelerated rational PROTAC design via deep learning and molecular simulations. Nature Machine Intelligence 2022;4:739–748 (融合高性能模拟和智能计算,7周即成功发现药代性能良好的PROTAC候选化合物).
- Zheng S#, Y Li#, S Chen, J Xu* and Yuedong Yang*. Predicting Drug Protein Interaction using Quasi-Visual Question Answering System. Nature Machine Intelligence 2020;2(1):134-140. (将蛋白质-药物相互作用问题转化为经典的视觉问答(VQA)问题,启发了分子相互作用研究新范式;荣获2021年世界人工智能大会青年优秀论文奖)
- Wang P, Zheng S, Jiang Y, Li C, Liu J, Wen C, Atanas P, Qian D*, Chen H*, Yuedong Yang*. Structure-aware multi-modal deep learning for drug-protein interactions prediction. J Chem Inf Model 2022; 62(5):1308–1317. (首次在超过4900万个数据点的工业级大数据上进行验证测试)
- Chen P, Ke Y, Lu Y, Du Y, Li J, Yan H, Zhao H, Zhou Y, Yuedong Yang*. DLIGAND2: an improved knowledge-based energy function for protein-ligand interactions using the distance-scaled, finite, ideal-gas reference state. J Cheminform 2019 Aug 7;11(1):52 (基于统计的自由能评估函数)
2) 药物分子优化
- Zheng S, Z Lei, H Ai, H Chen, D Deng*, Yuedong Yang*. Deep Scaffold Hopping with Multi-modal Transformer Neural Networks. J Cheminfo 2021; 13:87.(有效生成维持分子活性的情况下,生成其它方面性能优异的分子)
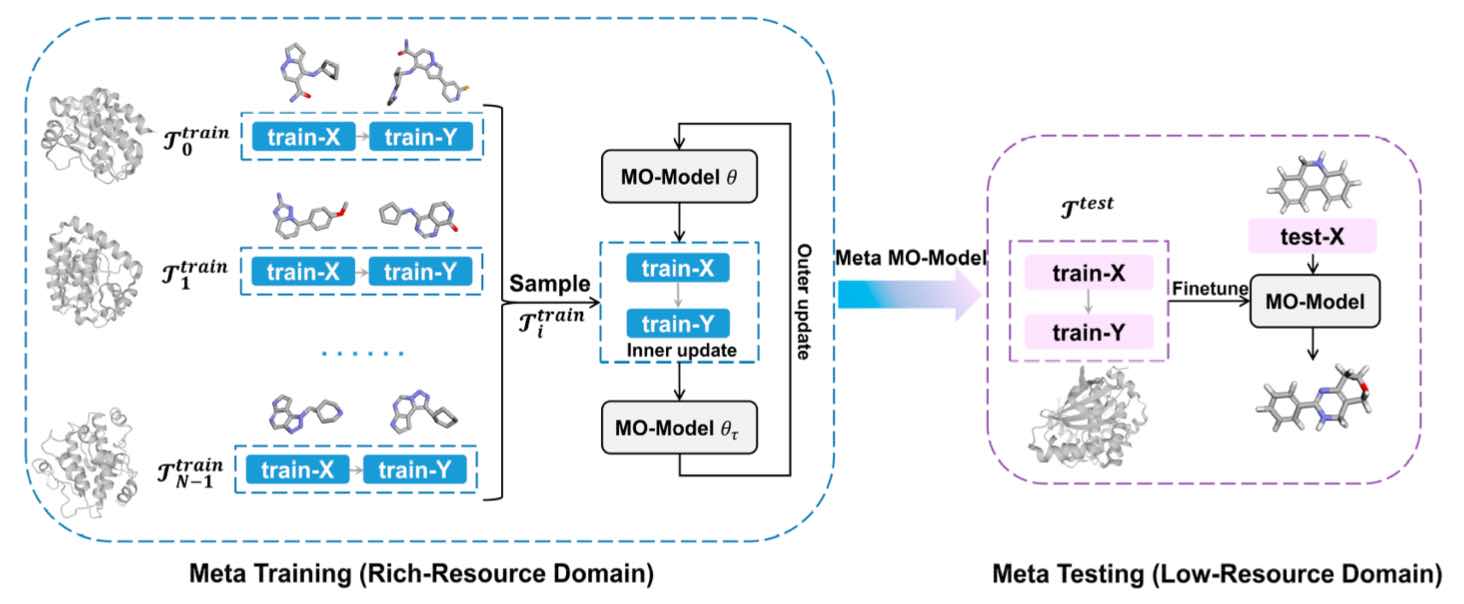
- Wang J, Zheng S, Chen J, Yuedong Yang*. Meta Learning for Low Resource Molecular Optimization. J Chem Inf Model 2021; (基于元学习的分子优化)
3) 分子逆合成预测
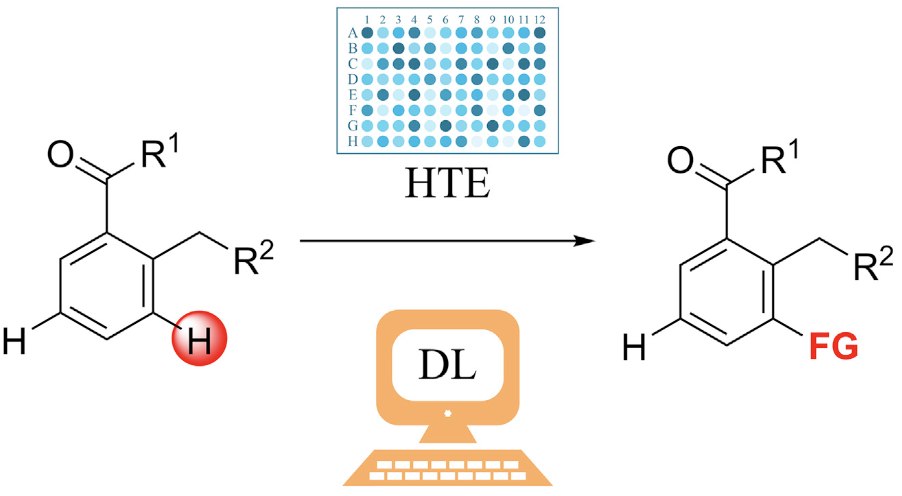
- Qiu J#, Xie J#,Su S, Gao Y, Meng H, Yuedong Yang*, Liao K*. Selective functionalization of hindered meta-C–H bond of o-alkylaryl ketones promoted by automation and deep learning. Chem 2022. (融合高通量和智能计算的新型化学反应预测)
- Zheng S, Rao J, Zhang Z, Xu J*, Yuedong Yang*. Predicting Retrosynthetic Reactions Using Self-Corrected Transformer Neural Networks. J Chem Inf Model. 2020 Jan 27;60(1):47-55.(最早将Transformer用于药物反应路径预测方法之一)
- Zheng S, T Zeng, C Li, B Chen, CW Coley, Yuedong Yang*, Ruibo Wu*. BioNavi-NP: Biosynthesis Navigator for Natural Products. Nat Comm 2022;13:3342. (天然产物逆合成预测)
多尺度多模态组学数据挖掘
随着组学数据多样化和规模化,能从多个时空尺度、不同视角全面阐释生物个体的状态,使得多组学数据分析扮演着越来越重要的角色。然而,多组学的多噪音、高维度、及变量间的复杂关系,需要借助先验知识,才能实现准确的多组学数据分析。
1) 单细胞数据分析
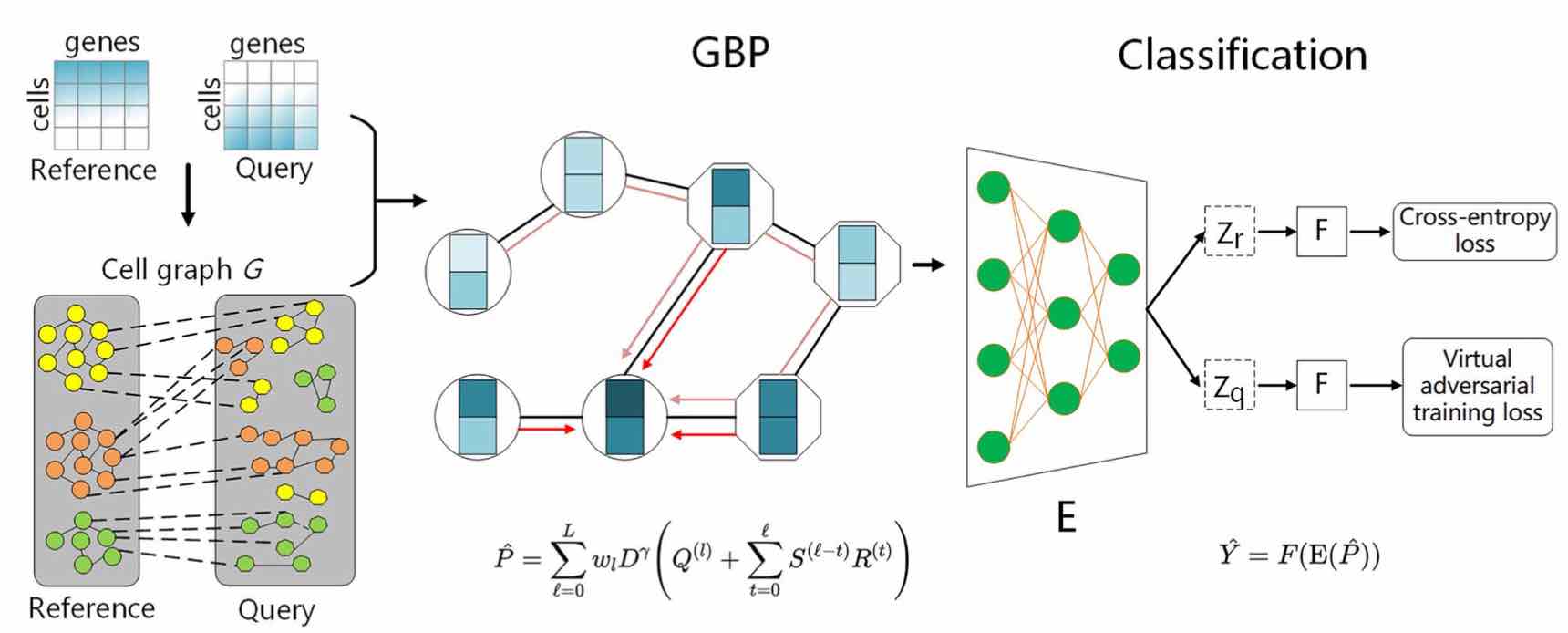
- Zeng Y, Zhou X, Pan Z, Lu Y*, Yuedong Yang*. A Robust and Scalable Graph Neural Network for Accurate Single Cell Classification. Brief in Bioinfo 2022; bbab570. (结合PageRank算法的超快速单细胞分类)
- Zeng Y, Wei Z, Yu W, Yin R, Li B, Tang Z, Lu Y, Yuedong Yang*. Spatial Transcriptomics Prediction from Histology jointly through Transformer and Graph Neural Networks. Brief in Bioinfo 2022. (基于病理图像的空转预测)
- Zeng Y, Wei Z, Zhong F, Pan Z, Lu Y, Yuedong Yang*. A Parameter-free Deep Embedded Clustering Method for Single-cell RNA-seq Data. Brief Bioinfo 2022 (无参单细胞聚类)
- Zhou X, Chai H, Zeng Y, Zhao H, Yuedong Yang*. scAdapt: Virtual adversarial domain adaptation network for single cell RNA-seq data classification across platforms and species. Brief in Bioinfo 2021, bbab281 & RECOMB 2021. (基于域对齐的批次消除)
- Rao J, Zhou X, Lu Y, Zhao H, Yuedong Yang*. Imputing Single-cell RNA-seq data by combining Graph Convolution and Autoencoder Neural Networks. iScience 2021; 24(5):102393 (第一个基于图卷积的数据补齐,获细胞出版社2021中国年度论文)
2) 疾病多组学数据分析
- Chai H, Zhou X, Zhang Z, Rao J, Zhao H, Yuedong Yang*. Integrating multi-omics data with deep learning for predicting cancer prognosis. Comput Biol Med 2021; 134:104481. (多组学癌症预后分析)
- Huang Z, H Chai, R Wang, H Wang, Yuedong Yang*, H Wu*. Integration of Patch Features through Self-Supervised Learning and Transformer for Survival Analysis on Whole Slide Images. MICCAI 2021. (基于病理图像的存活预测)
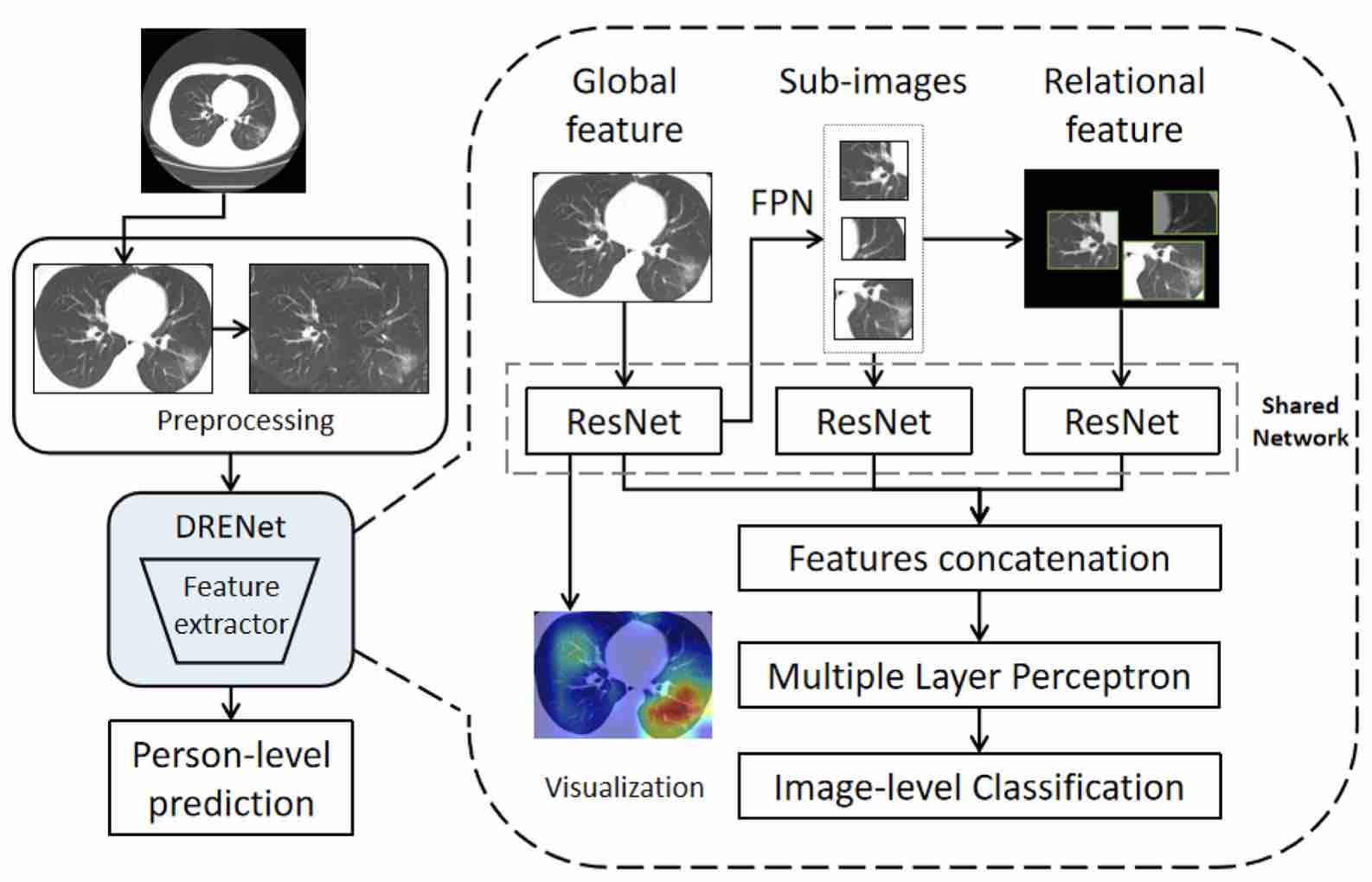
- Song Y, Zheng S, Li L, Zhang X, Zhang X, Huang Z, Chen J, Zhao H, Jie Y, Wang R, Chong Y*, Shen J*, Zha Y*, Yuedong Yang*. Deep learning Enables Accurate Diagnosis of Novel Coronavirus (COVID-19) with CT images. IEEE TCBB 2021;18(6):2775-2780. (最早的新冠CT诊断模型;cited>800;2021年度中国影像医学领域最高价值论文排名第一)
- Zhang Z, Chai H, Y Wang, Pan Z, Yuedong Yang*. Cancer survival prognosis with Deep Bayesian Perturbation Cox Network. Comput Biol Med 2021.(深度贝叶斯网络解决癌症预后删失数据问题)
- Y Wang, Z Zhang, H Chai, and Yuedong Yang*. Multi-omics Cancer Prognosis Analysis Based on Graph Convolution Network. BIBM 2021. (基于图网络的癌症预后)
联系方式
腾讯地址:广州市番禺区广州大学城外环东路132号中山大学东校区国家超级计算广州中心