Table of Contents
Lab Introduction

The group focuses on biomedical high-performance computing studies. Through the development of high-performance computing, big data and artificial intelligence algorithms, it solves major problems in biomedical science, empowers the biomedical industry, develops accurate and ultra-fast disease diagnosis and treatment and new drug research and development algorithms, and builds a large number based on Tianhe No. 2 According to the unified cloud supercomputing platform for analysis and calculation, it provides one-stop service for industrial applications.
With the rapid development of health big data, health medicine has become a hot spot in AI industry applications. Tencent, Alibaba, Huawei and other companies have all laid out relevant industrial development one after another. This year's fight against the epidemic has fully demonstrated the important role of big data analysis in human health. During the epidemic, the laboratory made full use of the super computing power of Tianhe 2 to carry out a series of work such as CT-based intelligent diagnosis, drug intelligent recommendation algorithm, and medical knowledge map, and achieved many important results. The project involves CV, NLP, ML, knowledge map and other fields. It has been widely used in various cutting-edge AI technologies. Students who are interested in any technology can find their own stage here.
At present, the main research contents include drug intelligence design, protein structure and function prediction, knowledge-driven multi-omics big data analysis, and the development of a biomedical high-performance computing platform based on Tianhe 2.
AI Drug Design
Focusing on the whole process of drug design, AI-based full-process algorithms have been developed, including drug screening, molecular optimization, ADMET property prediction, chemical synthesis route prediction, etc. Relevant representative work includes:
1) Drug Virtual Screening
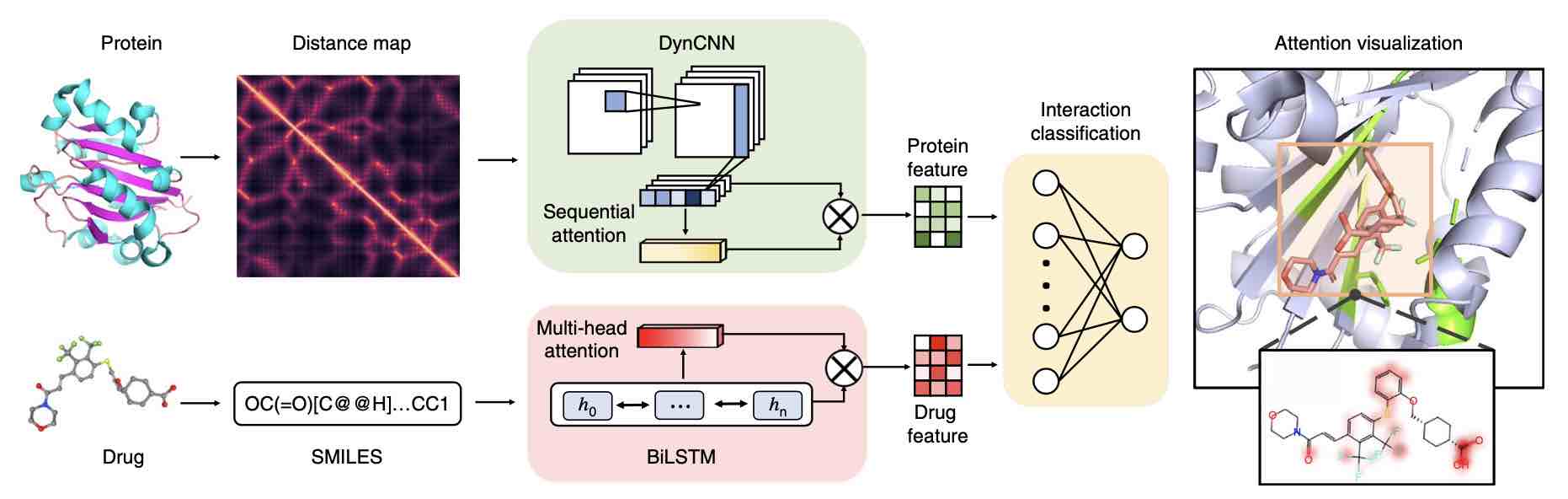
- Zheng S#, Y Li#, S Chen, J Xu* and Yuedong Yang*. Predicting Drug Protein Interaction using Quasi-Visual Question Answering System. Nature Machine Intelligence 2020;2(1):134-140. (Converting the protein-drug interaction problem into a classic visual question (VQA) question, as inspired a new paradigm of molecular interaction research. Winning the Youth Excellent Paper Award at the 2021 World Artificial Intelligence Conference)
- Wang P, Zheng S, Jiang Y, Li C, Liu J, Wen C, Atanas P, Qian D*, Chen H*, Yuedong Yang*. Structure-aware multi-modal deep learning for drug-protein interactions prediction. J Chem Inf Model 2022; 62(5):1308–1317. (For the first time of validation on industrial-grade big data with more than 49 million data points)
- Chen P, Ke Y, Lu Y, Du Y, Li J, Yan H, Zhao H, Zhou Y, Yuedong Yang*. DLIGAND2: an improved knowledge-based energy function for protein-ligand interactions using the distance-scaled, finite, ideal-gas reference state. J Cheminform 2019 Aug 7;11(1):52 (Statistics-based free energy function)
2) Property Prediction & GCN Algorithm
- Song Y# , S Zheng# , Z Niu , Z Fu , Y Lu and Yuedong Yang*. Communicative Representation Learning on Attributed Molecular Graphs. IJCAI 2020 (AI Top conference, DOI: 10.24963/ijcai.2020/388). (A new graph convolution model of CMPNN has been developed, which has made a breakthrough in drug property prediction)
- Chen J#, Zheng S#, Yuedong Yang*. Learning Attributed Graph Representation with Communicative Message Passing Transformer. IJCAI 2021. (New graph convolution framework of integrated CMPNN and Transformer)
3) Molecular Optimization
- Zheng S, Z Lei, H Ai, H Chen, D Deng*, Yuedong Yang*. Deep Scaffold Hopping with Multi-modal Transformer Neural Networks. J Cheminfo 2021; 13:87.(Effectively generate molecules with excellent performance in other aspects while maintaining molecular activity)
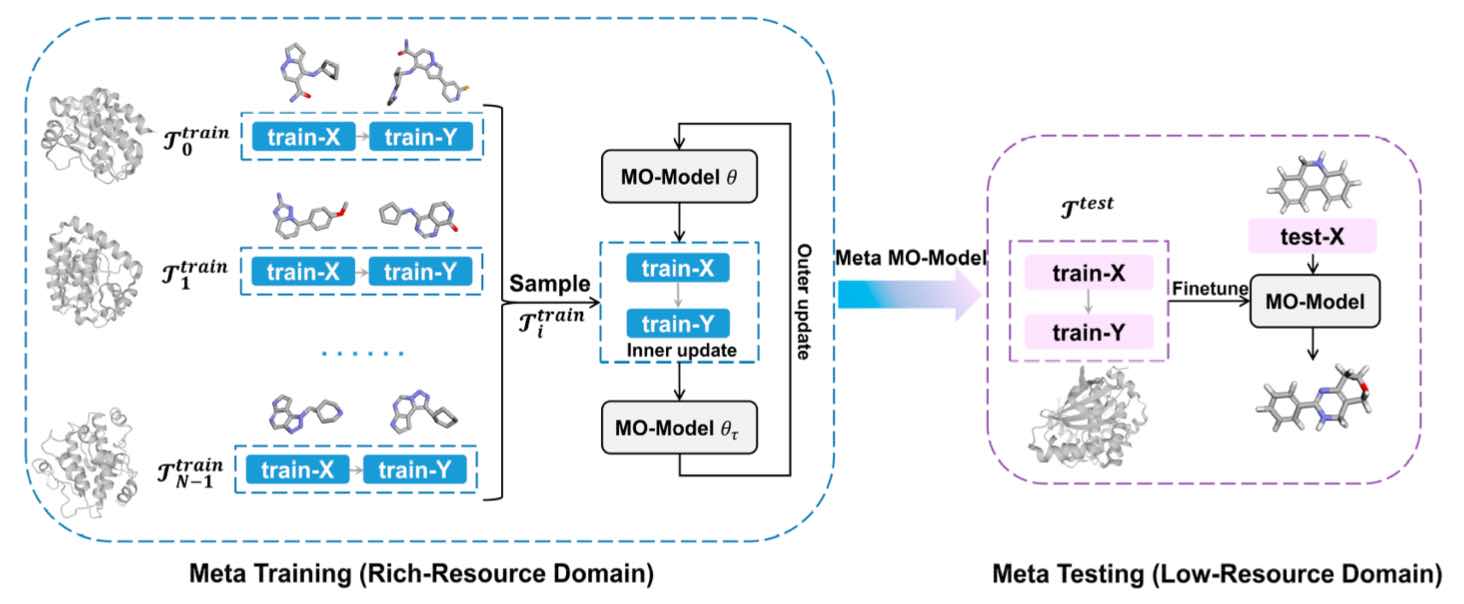
- Wang J, Zheng S, Chen J, Yuedong Yang*. Meta Learning for Low Resource Molecular Optimization. J Chem Inf Model 2021; (Meta-learning based Molecular Optimization)
- Zheng S, Rao J, Zhang Z, Xu J*, Yuedong Yang*. Predicting Retrosynthetic Reactions Using Self-Corrected Transformer Neural Networks. J Chem Inf Model. 2020 Jan 27;60(1):47-55.(For the first time to use Transformer for drug response path prediction )
Protein Structure and Function Prediction
Proteins are one of the most important macromolecules in organisms. They participate in almost all life activities. Accurately predicting the three-dimensional spatial structure and folding process of proteins is listed as one of the major scientific difficulties in the 21st century. Since 2013, PI has developed the SPIDER series of protein secondary structure prediction using deep learning technology, which is one of the earliest studies in the world to use deep learning for protein secondary structure prediction. Since then, it has continuously introduced multitasking learning, model iterative training and other strategies, and has made structural prediction from the past. The discrete state of the secondary structure is converted into continuous numerical prediction.
1) Protein function prediction
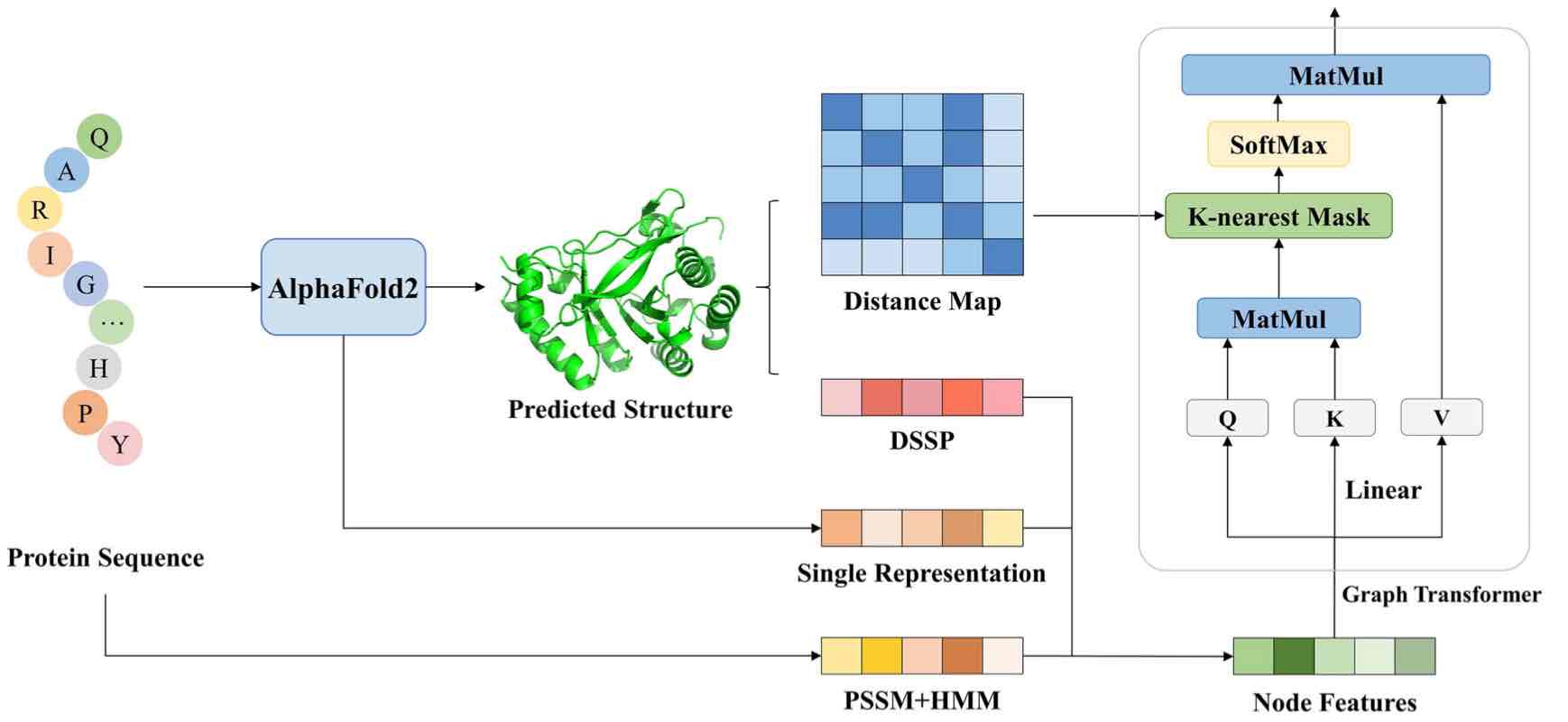
- Yuan Q, Chen S, Rao J, Zheng S, Zhao H, Yuedong Yang*. AlphaFold2-aware protein-DNA binding site prediction using graph transformer. Brief in Bioinfo 2022; bbab564 . (Alphafold2-based binding site prediction)
- Yuan Q, Chen J, Zhao H, Zhou Y*, Yuedong Yang*. Structure-aware protein-protein interaction site prediction using deep graph convolutional network. Bioinformatics 2021; btab643. (Predicting binding site through GCN)
- Chen J, Zheng S, Zhao H, Yuedong Yang*. Structure-aware Protein Solubility Prediction From Sequence Through Graph Convolutional Network And Predicted Contact Map. J Cheminfo 2021; 13(1):7 (The first study for sequence-based protein property prediction through GCN on predicted contact map)
2) Protein structure prediction
- J Lyons, A Dehzangi, R Heffernan, A Sharmaa, K Paliwal, A Sattar, Y Zhou*, Yuedong Yang*. Predicting backbone Calpha angles and dihedrals from protein sequences by stacked sparse auto-encoder deep neural network. J Comput Chem. 2014; 35(28):2040-6. doi: 10.1002/jcc.23718. (SPIDER,the earliest study to predict continuous torsion angle values through deep learning)
- Yuedong Yang , J Gao, J Wang, R Heffernan, J Hanson, K Paliwal, and Y Zhou. Sixty-five years of long march in protein secondary structure prediction: the final stretch? Brief in Bioinfo 2018 May 1;19(3):482-494. (SPIDER,secondary structure prediction)
- Heffernan R, Yuedong Yang*, Paliwal K, Zhou Y*. Capturing Non-Local Interactions by Long Short Term Memory Bidirectional Recurrent Neural Networks for Improving Prediction of Protein Secondary Structure, Backbone Angles, Contact Numbers, and Solvent Accessibility. Bioinformatics. 2017 Sep 15;33(18):2842-2849.
3) Protein tertiary structure prediction
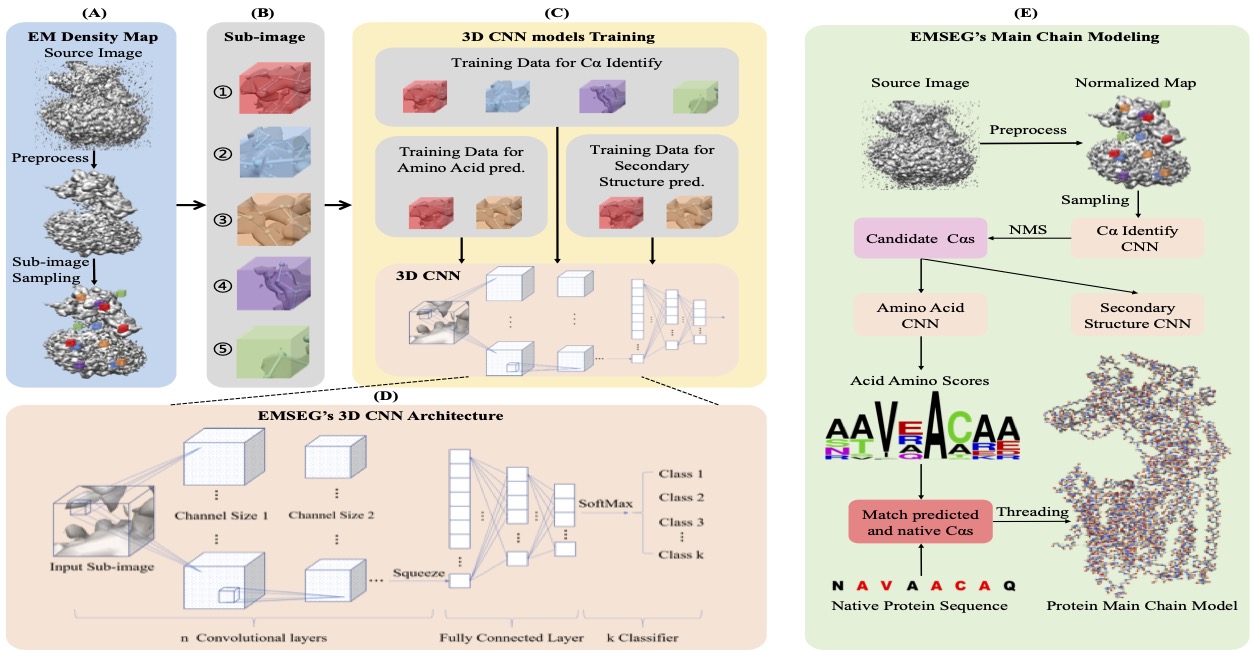
- Chen S, Zhang S, Li X, Liu Y, and Yuedong Yang*. SEGEM: a Fast and Accurate Automatic Protein Backbone Structure Modeling Method for Cryo-EM. BIBM 2021.
- Yuedong Yang, Faraggi E, H Zhao, Zhou Y. Improving protein fold recognition and template-based modeling by employing probabilistic-based matching between predicted one-dimensional structural properties of the query and corresponding native properties of templates. Bioinformatics 2011 Aug 1;27(15):2076-82.
- Cai Y, Li X, Sun Z, Lu Y, Zhao H, Hanson J, Paliwal K, Litfin T, Zhou Y*, Yuedong Yang*. SPOT-Fold: Fragment-Free Protein Structure Prediction Guided by Predicted Backbone Structure and Contact Map. J Comput Chem. 2020 Mar 30;41(8):745-750.
Multi-omics data analysis
With the diversification and scale of histological data, the state of biological individuals can be comprehensively explained from multiple spatiotemporal scales and different perspectives, so that multiomics data analysis plays an increasingly important role. However, the multi-noise, high-dimensional, and complex relationship between variables of multiomics requires the help of prior knowledge to achieve accurate multi-omics data analysis.
1) Biomedical knowledge graph
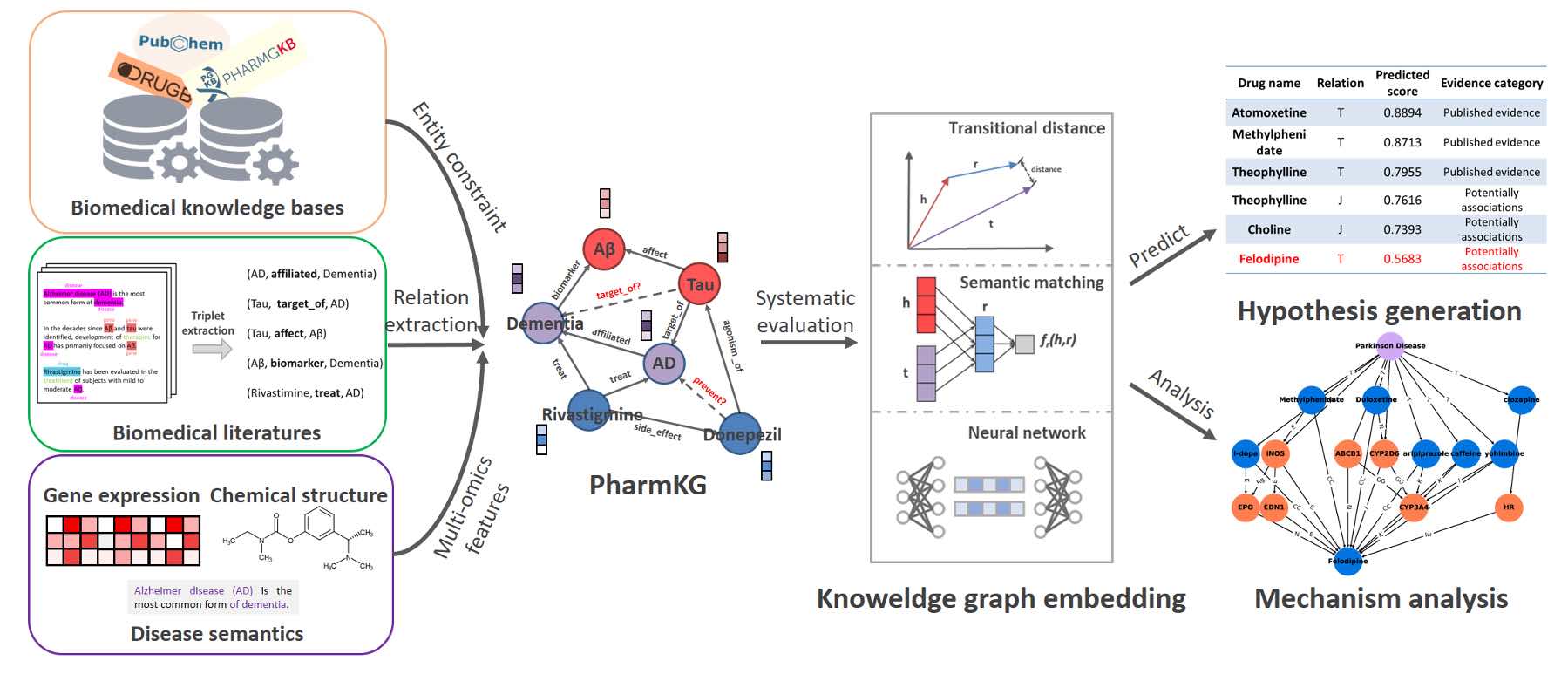
- Rao J, Zheng S, Mai S, Yuedong Yang*.Communicative Subgraph Representation Learning for Multi-Relational Inductive Drug-Gene Interaction Prediction. IJCAI 2022. (Predicting drug-gene interaction through subgraph learning)
- Zheng S#, Rao J#, Song Y, Zhang J, Xiao X, Fang EF, Yuedong Yang*, Niu Z*. PharmKG: A Dedicated Knowledge Graph Benchmark for Biomedical Data Mining. Brief in Bioinfo 2020 (IF=9.0); doi:10.1093/bib/bbaa344. (PharmKG: multi-source integration from public database including OMIM、DrugBank,and recent literature,leading to 8000 entities including genes, drug, and diseases, and 29 classes of >50 million relations)
- Mai S#, Zheng S#, Yuedong Yang*, Hu H*. Communicative Message Passing for Inductive Relation Reasoning. AAAI 2021(CoMPILE: Inductive learning)
2) scRNA-seq data analysis
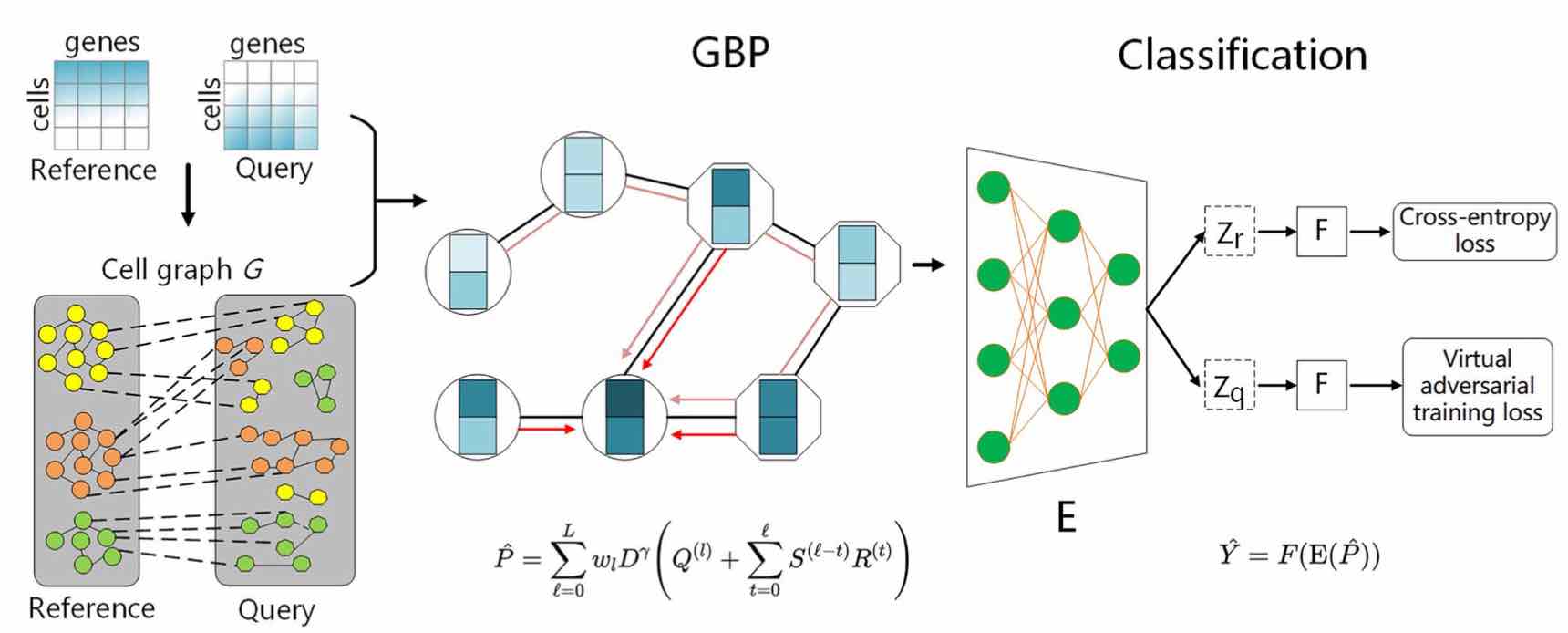
- Rao J, Zhou X, Lu Y, Zhao H, Yuedong Yang*. Imputing Single-cell RNA-seq data by combining Graph Convolution and Autoencoder Neural Networks. iScience 2021; 24(5):102393 (the earliest study to apply GCN into scRNA-seq data analysis; Cell Press 2021 Annual Paper Award in China)
- Zeng Y, Zhou X, Pan Z, Lu Y*, Yuedong Yang*. A Robust and Scalable Graph Neural Network for Accurate Single Cell Classification. Brief in Bioinfo 2022; bbab570. (Superfast cell classification by PageRank algorithm)
- Zeng Y, Wei Z, Zhong F, Pan Z, Lu Y, Yuedong Yang*. A Parameter-free Deep Embedded Clustering Method for Single-cell RNA-seq Data. Brief Bioinfo 2022.
- Zhou X, Chai H, Zeng Y, Zhao H, Yuedong Yang*. scAdapt: Virtual adversarial domain adaptation network for single cell RNA-seq data classification across platforms and species. Brief in Bioinfo 2021, bbab281 & RECOMB 2021.
3) Multi-omics analysis
- Chai H, Zhou X, Zhang Z, Rao J, Zhao H, Yuedong Yang*. Integrating multi-omics data with deep learning for predicting cancer prognosis. Comput Biol Med 2021; 134:104481.
- Huang Z, H Chai, R Wang, H Wang, Yuedong Yang*, H Wu*. Integration of Patch Features through Self-Supervised Learning and Transformer for Survival Analysis on Whole Slide Images. MICCAI 2021.
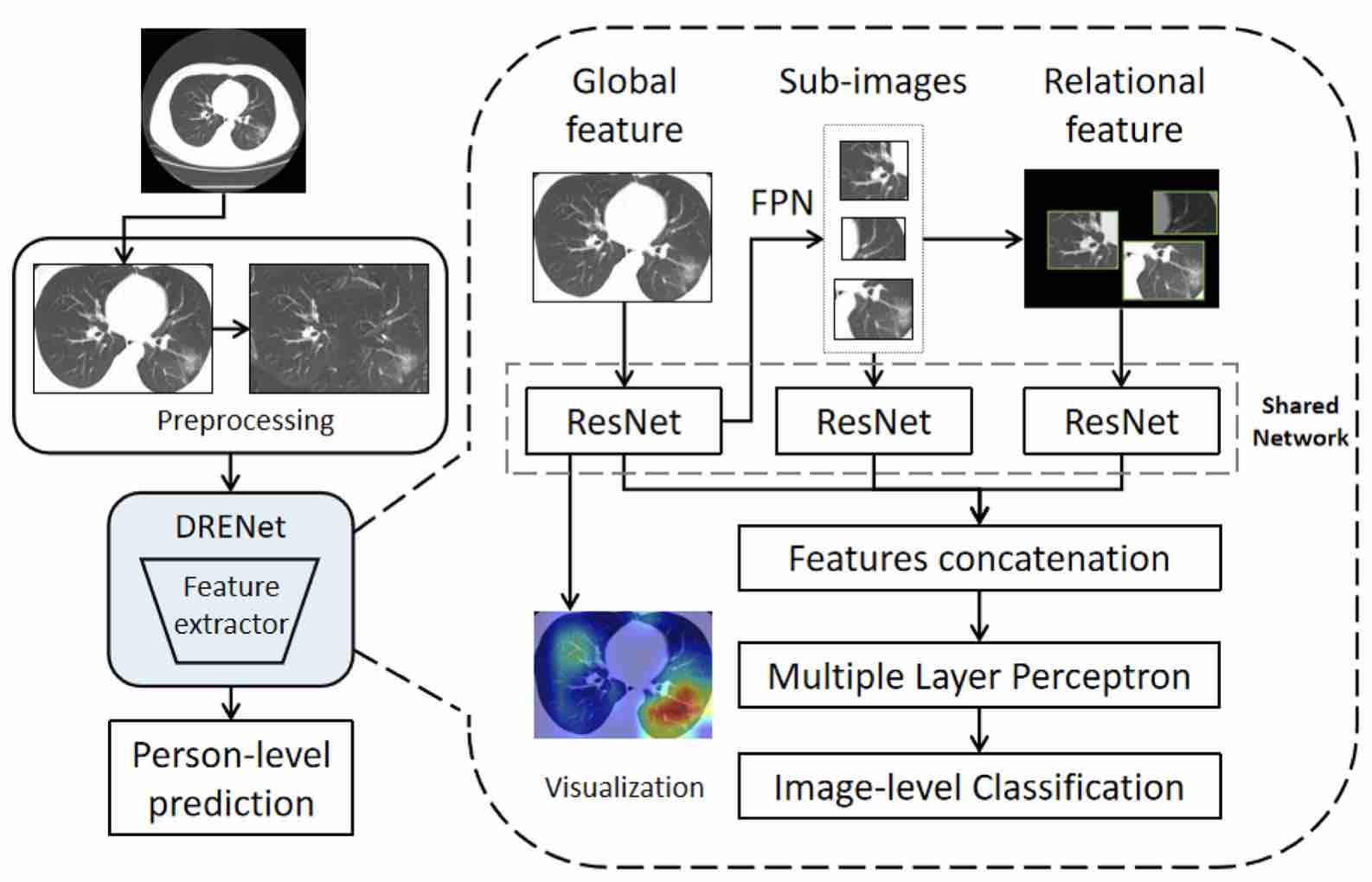
- Song Y, Zheng S, Li L, Zhang X, Zhang X, Huang Z, Chen J, Zhao H, Jie Y, Wang R, Chong Y*, Shen J*, Zha Y*, Yuedong Yang*. Deep learning Enables Accurate Diagnosis of Novel Coronavirus (COVID-19) with CT images. IEEE TCBB 2021;18(6):2775-2780. (the earliest AI diagnosis model for COVID-19; the Most Valued Articles in the Field of Medical Image in China)